阿里云-自然语言处理(1936)-支持文档
[TOC]
将连续的自然语言文本,切分成具有语义合理性和完整性的词汇序列,同时保持对数据、模型的不断迭代更新,目前支持简体中文、英文及泰文。
# 1. 准备参数
##### (1) lang输入框的参数:
要处理的语言支持的选项:
ZH_Big(中文大粒度)
ZH(中文中粒度)
ZH_Small(中文小粒度)
以“多语言分词”为例:
中文大粒度:"多语言分词"。
中文中粒度:"多语言","分词"。
中文小粒度:"多,"语言","分词"。
EN(英文)
例如:
text:"wouldyoulikesomemeat"
会被分为"would" , "you" , "like" , "some" , "meat"
中间的空格会被单独拆分。
text:"would you like some meat"
会被分为"would" , "" , "you" , "" , "like" , "" , "some" , "" , "meat"
TH(泰语)
可选,默认ZH。
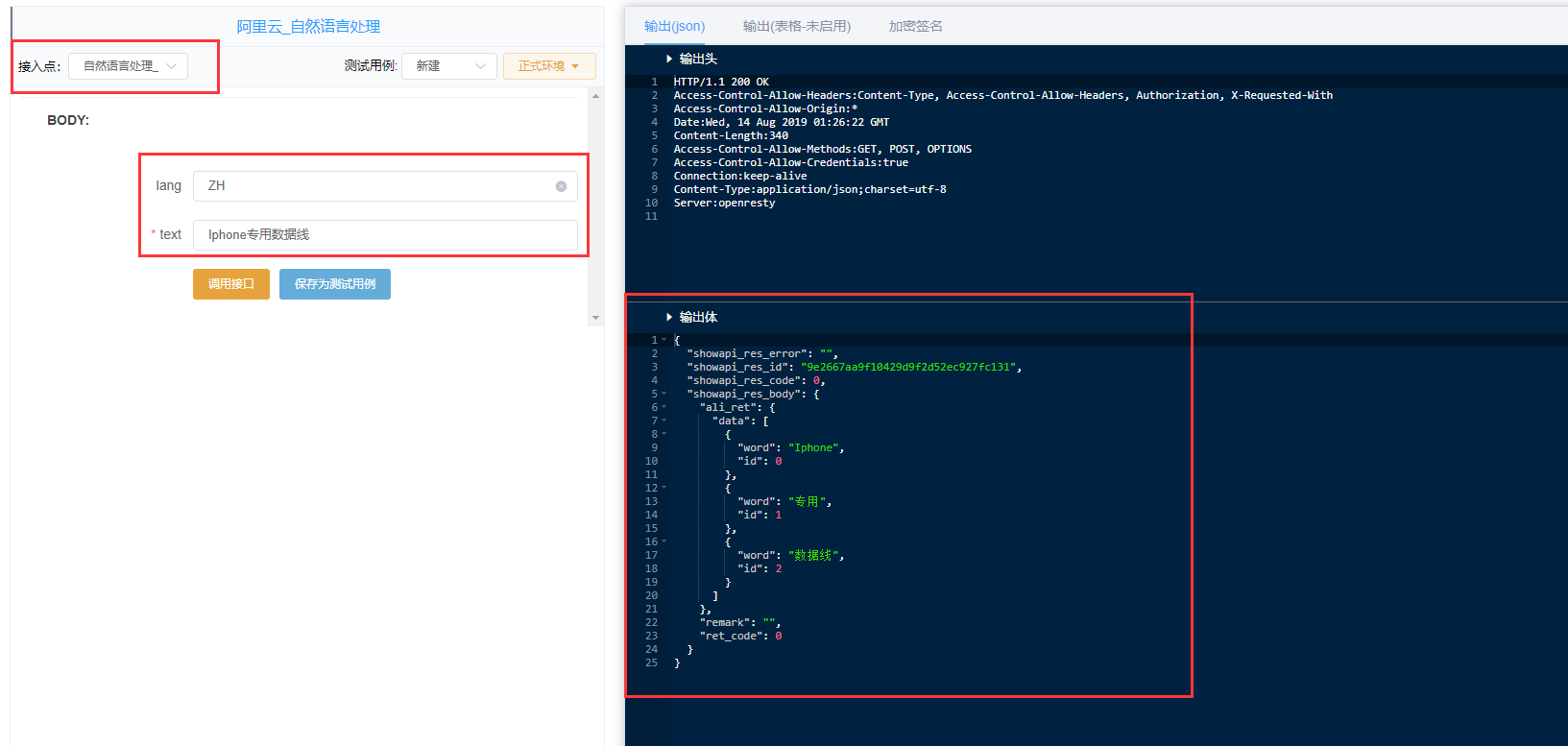
##### (2) text输入框的参数:
要处理的文本,例如:Iphone专用数据线
# 2. 在易源测试页面进行调用
进入[易源测试界面](https://www.showapi.com/apiGateway/onlineTest?apiCode=1936&pointCode=1 "易源测试界面"),输入上述参数并进行调用,结果如图: