废弃(2005)-支持文档
[TOC]
#### 接口简介
短文本相似度接口用来判断两个文本的相似度得分。
关于请求参数中model的选择:
**BOW(词包)模型**
基于bag of words的BOW模型,特点是泛化性强,效率高,比较轻量级,适合任务:输入序列的 term “确切匹配”、不关心序列的词序关系,对计算效率有很高要求;
**GRNN(循环神经网络)模型**
基于recurrent,擅长捕捉短文本“跨片段”的序列片段关系,适合任务:对语义泛化要求很高,对输入语序比较敏感的任务;
**CNN(卷积神经网络)模型**
模型语义泛化能力介于 BOW/RNN 之间,对序列输入敏感,相较于 GRNN 模型的一个显著优点是计算效率会更高些
# 1.准备两篇相似的短文
百度智能云官方给出的示例文本为
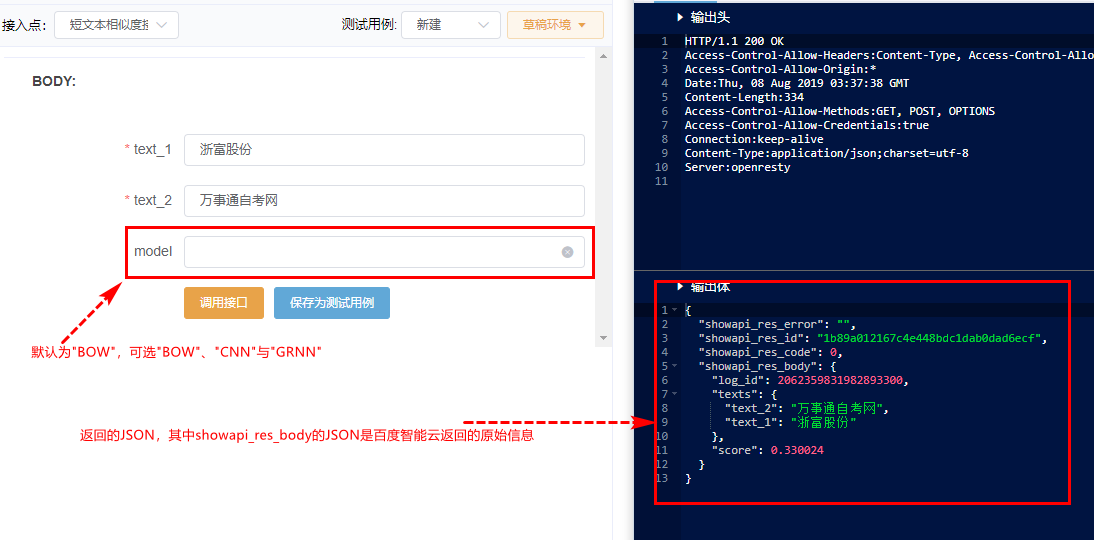
>文本1:浙富股份
文本2:万事通自考网
下面我们就调用接口来获得一下两个文本的相似度量化值
**温馨提示:根据百度智慧云自然语言处理官方[文档](https://cloud.baidu.com/doc/NLP/s/8jwvylhqi/ "文档"),自然语言处理接口可以使用两种(GBK、UTF-8)字符编码进行调用,为了兼容不同的字符编码,我们在【自然语言处理】连接器中保留了通过不同字符编码调用的功能,若您的系统使用的字符编码为UTF-8则无需进行多余操作,若您的系统使用的是GBK编码,您需对连接器的设置作出小小的改动,具体修改方式点击[这里](https://www.showapi.com/book/view/3681/16 "这里")查看**
#2.在易源测试页面进行调用
进入[易源测试界面](https://www.showapi.com/apiGateway/onlineTest?env=draft&apiCode=2005&pointCode=3 "易源测试界面") 输入上述文本并进行调用,结果如图: